Neural Architecture Search Algorithms
This page describes how Neural Architecture Search (NAS) algorithms work in Katib.
Efficient Neural Architecture Search (ENAS)
The algorithm follows the idea proposed in Efficient Neural Architecture Search via Parameter Sharing by Hieu Pham, Melody Y. Guan, Barret Zoph, Quoc V. Le and Jeff Dean (https://arxiv.org/abs/1802.03268) and Neural Architecture Search with Reinforcement Learning by Barret Zoph and Quoc V. Le (https://arxiv.org/abs/1611.01578) .
The implementation is based on the GitHub of Efficient Neural Architecture Search via Parameter Sharing and Google Implementation for ENAS. It uses a recurrent neural network with LSTM cells as controller to generate neural architecture candidates. And this controller network is updated by policy gradients. However, it currently does not support parameter sharing.
Katib Implementation
Katib represents neural network in the specific format. If number of layers (n) = 12 and number of possible operations (m) = 6, the definition of an architecture will be like:
[2]
[0 0]
[1 1 0]
[5 1 0 1]
[1 1 1 0 1]
[5 0 0 1 0 1]
[1 1 1 0 0 1 0]
[2 0 0 0 1 1 0 1]
[0 0 0 1 1 1 1 1 0]
[2 0 1 0 1 1 1 0 0 0]
[3 1 1 1 1 1 1 0 0 1 1]
[0 1 1 1 1 0 0 1 1 1 1 0]
There are n rows, the ith row has i elements and describes the ith layer. Please notice that layer 0 is the input and is not included in this definition.
In each row, the first integer ranges from 0 to m-1 and indicates the operation in this layer. Starting from the second position, the kth integer is a boolean value that indicates whether (k-2)th layer has a skip connection with this layer. (There will always be a connection from (k-1)th layer to kth layer)
Output of GetSuggestion()
The output of GetSuggestion() from the algorithm service consists of two parts:
architecture and nn_config.
architecture is a json string of the definition of a neural architecture. The format is as stated
above. One example is:
[[27], [29, 0], [22, 1, 0], [13, 0, 0, 0], [26, 1, 1, 0, 0], [30, 1, 0, 1, 0, 0], [11, 0, 1, 1, 0, 1, 1], [9, 1, 0, 0, 1, 0, 0, 0]]
nn_config is a json string of the detailed description of what is the num of layers,
input size, output size and what each operation index stands for. A nn_config corresponding to
the architecture above can be:
{
"num_layers": 8,
"input_sizes": [32, 32, 3],
"output_sizes": [10],
"embedding": {
"27": {
"opt_id": 27,
"opt_type": "convolution",
"opt_params": {
"filter_size": "7",
"num_filter": "96",
"stride": "2"
}
},
"29": {
"opt_id": 29,
"opt_type": "convolution",
"opt_params": {
"filter_size": "7",
"num_filter": "128",
"stride": "2"
}
},
"22": {
"opt_id": 22,
"opt_type": "convolution",
"opt_params": {
"filter_size": "7",
"num_filter": "48",
"stride": "1"
}
},
"13": {
"opt_id": 13,
"opt_type": "convolution",
"opt_params": {
"filter_size": "5",
"num_filter": "48",
"stride": "2"
}
},
"26": {
"opt_id": 26,
"opt_type": "convolution",
"opt_params": {
"filter_size": "7",
"num_filter": "96",
"stride": "1"
}
},
"30": {
"opt_id": 30,
"opt_type": "reduction",
"opt_params": {
"reduction_type": "max_pooling",
"pool_size": 2
}
},
"11": {
"opt_id": 11,
"opt_type": "convolution",
"opt_params": {
"filter_size": "5",
"num_filter": "32",
"stride": "2"
}
},
"9": {
"opt_id": 9,
"opt_type": "convolution",
"opt_params": {
"filter_size": "3",
"num_filter": "128",
"stride": "2"
}
}
}
}
This neural architecture can be visualized as:
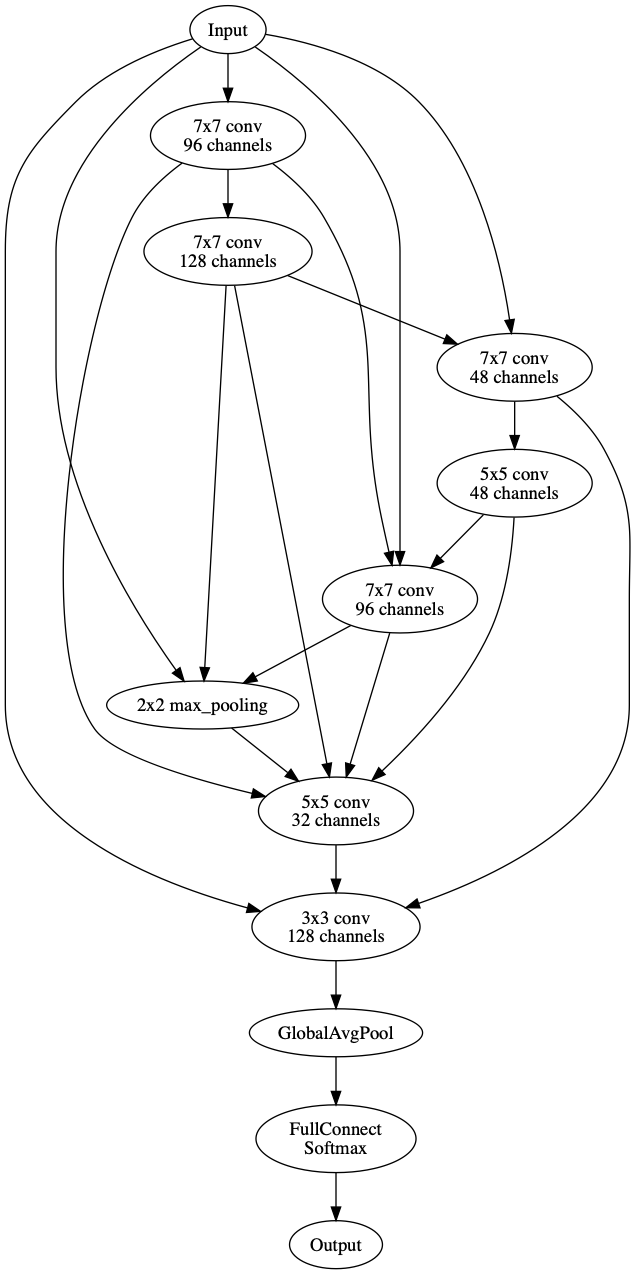
The following items can be implemented in Katib to better support ENAS:
- Add ‘micro’ mode, which means searching for a neural cell instead of the whole neural network.
- Add support for recurrent neural networks and build a training container for the Penn Treebank task.
- Add parameter sharing, if possible.
- Change LSTM cell from self defined functions in LSTM.py to
tf.nn.rnn_cell.LSTMCell - Store the Suggestion checkpoint to PVC to protect against unexpected enas service pod restarts
- Add
RequestCountinto API so that the Suggestion can clean the information of completed studies.
Differentiable Architecture Search (DARTS)
The algorithm follows the idea proposed in DARTS: Differentiable Architecture Search by Hanxiao Liu, Karen Simonyan, Yiming Yang: https://arxiv.org/abs/1806.09055. The implementation is based on official github implementation and popular repository.
The algorithm addresses the scalability challenge of architecture search by formulating the task in a differentiable manner. It is based on continuous relaxation and gradient descent in the search space. It is able to efficiently design high-performance convolutional architectures for image classification (on CIFAR-10 and ImageNet) and recurrent architectures for language modeling (on Penn Treebank and WikiText-2).
Katib Implementation
To support DARTS in current Katib functionality the implementation follows this way:
DARTS Suggestion service creates set of primitive operations from the Experiment search space. For example:
['separable_convolution_3x3', 'dilated_convolution_3x3', 'dilated_convolution_5x5', 'avg_pooling_3x3', 'max_pooling_3x3', 'skip_connection']Suggestion returns algorithm settings, number of layers and set of primitives to Katib Controller
Katib controller starts DARTS training container with the appropriate settings and all possible operations.
Training container runs DARTS algorithm.
Metrics collector saves Best Genotype from the training container log.
Best Genotype representation
Best Genotype is the best cell for each neural network layer. Cells are generated by DARTS algorithm. Here is an example of the Best Genotype:
Genotype(
normal=[
[('max_pooling_3x3',0),('max_pooling_3x3',1)],
[('max_pooling_3x3',0),('max_pooling_3x3',1)],
[('max_pooling_3x3',0),('dilated_convolution_3x3',3)],
[('max_pooling_3x3',0),('max_pooling_3x3',1)]
],
normal_concat=range(2,6),
reduce=[
[('dilated_convolution_5x5',1),('separable_convolution_3x3',0)],
[('max_pooling_3x3',2),('dilated_convolution_5x5',1)],
[('dilated_convolution_5x5',3),('dilated_convolution_5x5',2)],
[('dilated_convolution_5x5',3),('dilated_convolution_5x5',4)]
],
reduce_concat=range(2,6)
)
In this example you can see 4 DARTS nodes with indexes: 2,3,4,5.
reduce parameter is the cells which located at the 1/3 and 2/3 of the total neural network layers.
They represent reduction cells in which all the operations adjacent to the input nodes are of stride two.
normal parameter is the cells which is located at the rest neural network layers.
They represent normal cell.
In CNN all reduce and normal intermediate nodes are concatenated and each node has 2 edges.
Each element in normal array is the node which has 2 edges. First element is the operation on
the edge and second element is the node index connection. Note that index 0 is the C_{k-2} node
and index 1 is the C_{k-1} node.
For example [('max_pooling_3x3',0),('max_pooling_3x3',1)] means that C_{k-2} node connects to
the first node with max_pooling_3x3 operation (Max Pooling with filter size 3) and C_{k-1}
node connects to the first node with max_pooling_3x3 operation.
reduce array follows the same way as normal array.
normal_concat and reduce_concat means concatenation between intermediate nodes.
Currently, it supports running only on single GPU and second-order approximation, which produced better results than first-order.
The following items can be implemented in DARTS:
Support multi GPU training. Add functionality to select GPU for training.
Support DARTS in Katib UI.
Think about better representation of Best Genotype.
Add more dataset for CNN. Currently, it supports only CIFAR-10.
Support RNN in addition to CNN.
Support micro mode, which means searching for a particular neural network cell.
Feedback
Was this page helpful?
Thank you for your feedback!
We're sorry this page wasn't helpful. If you have a moment, please share your feedback so we can improve.