Overview

What is Kubeflow Hub?
Kubeflow Hub (formerly known as Model Registry) is the central component in Kubeflow for managing the full lifecycle of ML models. It brings together two complementary capabilities under one project:
- Model Registry — a metadata store where teams register, version, and track their own models, model versions, and artifacts as they move from experimentation to production.
- Model Catalog — a read-only discovery service that aggregates models from external catalog sources, letting users search and browse curated models before registering or deploying them.
Together, Model Registry and Model Catalog cover the full model-management workflow: discover a model in the catalog, register it in the registry, version and govern it through the ML lifecycle, and deploy it to production.
What is Model Registry?
The Model Registry is a central index for ML model developers to manage models, versions, and ML artifacts metadata. It fills a gap between model experimentation and production activities, providing a central interface for all stakeholders in the ML lifecycle to collaborate on ML models.
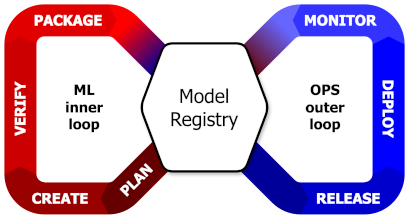

The Model Registry supports every stage of the ML lifecycle:
- Create: facilitates collaboration between different teams in order to track changes, experiment with different model architectures, and maintain a history of model iterations.
- Verify: supports rigorous testing and validation before progressing further, maintaining a record of performance metrics and test results for each version.
- Package: assists in organizing model artifacts and dependencies, enabling seamless integration with deployment pipelines and ensuring reproducibility across environments.
- Release: manages the transition of validated versions to production-ready status, helping organizations to maintain versioning conventions and facilitating approval workflows.
- Deploy: provides information about the approved model versions and associated artifacts, ensuring consistency and traceability across deployment environments.
- Monitor: supports ongoing performance monitoring and model drift detection by maintaining a comprehensive record of deployed models and linking to their performance metrics, facilitating proactive maintenance and retraining as needed.
DevOps, Data Scientists, and developers need to collaborate with other users in the ML workflow to get models into production. Data scientists need an efficient way to share model versions, artifacts and metadata with other users that need access to those models as part of the MLOps workflow.
What is Model Catalog?
The Model Catalog is a read-only discovery service for ML models across multiple catalog sources. It acts as a federated metadata aggregation layer, allowing users to search and discover models from various external catalogs through a unified interface.
Key capabilities
- Federated discovery: browse models from multiple catalog sources in a single view, without needing to visit each source individually.
- Pluggable sources: add new catalog sources via configuration. Currently supported source types include:
- YAML Catalog — static YAML files containing curated model metadata.
- Hugging Face Hub — discover models directly from Hugging Face’s model repository, with support for organization-scoped and pattern-based model inclusion/exclusion.
- Rich metadata: each catalog model exposes metadata such as description, provider, tasks, languages, license information, and extensible custom properties.
- Filtering and search: filter models by task, provider, license, language, and other properties. Custom properties like
model_type(generative vs. predictive) enable further classification. - Model registration: once you find a model in the catalog, you can register it directly into a Model Registry to begin versioning, governing, and deploying it.
How it works
The catalog service operates as a metadata aggregation layer that:
- Reads catalog source configurations (YAML files or Hugging Face API connections).
- Federates model metadata from those sources into a unified REST API.
- Provides search, filtering, and detail endpoints for the UI and programmatic access.
The catalog does not store model weights or artifacts — it provides metadata and references to where models can be found in their source repositories.
For the API specification, see the Model Catalog REST API reference.
Use Cases
This section describes Model Registry use-cases in the context of a MLOps Platform with Model Training, Experimentation, and Deployment.
A company, ACME Inc., is developing a machine-learning model for predicting customer churn. They require a centralized model registry for their MLOps platform (based on Kubeflow) for managing their ML model development lifecycle, including training, experimentation, and deployment. They want to ensure model governance, reproducibility, and efficient collaboration across data scientists and engineers.
Personas
- Data Scientist: develops and evaluates different models for customer churn prediction. Tracks the performance of various model versions to compare them easily.
- MLOps Engineer: deploys the chosen model into production. Uses the latest model version and its metadata to configure the deployment environment.
- Business Analyst: Monitors the deployed model’s performance and makes decisions based on its predictions. Uses model lineage and metadata to drive business outcomes.
Use Case 1: Tracking the Training of Models
The Data Scientist uses Kubeflow Notebooks to perform exploratory research and trains several types of models, with different hyperparameters and metrics. The Kubeflow Model Registry is used to track those models, in order to make comparisons and identify the best-performing model. Once the champion model is selected, the Data Scientist shares the model with the team by maintaining the appropriate status flag on the registry. The Data Scientist also tracks the lineage of training data sources and notebook code.
- Track models available on storage: once the model is stored, it can then be tracked in the Kubeflow Model Registry for managing its lifecycle. The Model Registry can catalog, list, index, share, record, organize this information. This allows the Data Scientist to compare different versions and revert to previous versions if needed.
- Track and compare performance: View key metrics like accuracy, recall, and precision for each model version. This helps identify the best-performing model for deployment.
- Create lineage: Capture the relationships between data, code, and models. This enables the Data Scientist to understand the origin of each model and reproduce specific experiments.
- Collaborate: Share models and experiment details with the MLOps Engineer for deployment preparation. This ensures a seamless transition from training to production.
Use Case 2: Experimenting with Different Model Weights to Optimize Model Accuracy
The Data Scientist after identifying a base model, uses Kubeflow Pipelines, Katib, and other components to experiment model training with alternative weights, hyperparameters, and other variations to improve the model’s performance metrics; Kubeflow Model Registry can be used to track data related to experiments and runs for comparison, reproducibility and collaboration.
- Register the Base Model: Track the Base Model storage location along with hyperparameters in the Model Registry.
- Track Experiments/Runs: With Kubeflow pipelines or using the Kubeflow Notebooks, track every variation of the hyper-parameters along with any configuration in that specific Experiment. With each run the different parameters can be tracked in the Model Registry.
- Track and compare performance: with each run view key metrics like accuracy, recall, and precision. This helps the Data Scientist identify the best-performing run/experiment for deployment.
- Reproducibility: if needed, the data tracked in Model Registry can be replayed to perform again the experiment/run to reproduce the models.
- Collaborate: Share models and experiment details with the MLOps Engineer for deployment preparation. This ensures a seamless transition from training to production.
Use Case 3: Model Deployment
The MLOps Engineer uses Kubeflow Model Registry to locate the most recent version for a given model, verify it is approved for deployment, understand model format, architecture, hyperparameters, and performance metrics to configure the serving environment; once deployed, Model Registry is used to continue monitoring and track deployed models for performance and mitigate drift.
- Retrieve the latest model version: Easily access the model version approved for deployment.
- Access model metadata: Understand the model’s architecture, hyperparameters, and performance metrics. This helps the MLOps engineer to configure the deployment environment and monitor performance after deployment.
- Manage serving configurations: Define how the model will be served to production applications and set up necessary resources.
- Track model deployments: Monitor the deployed model’s performance and track its health over time. This allows the MLOps Engineer to identify potential issues and take corrective actions.
Use Case 4: Monitoring and Governance
The Business Analyst uses Kubeflow Model Registry to audit deployed models, monitor model performance by integrating with observability tools to track key metrics and identify when model is drifting or needs re-training; capabilities of model lineage enable identifying all related artifacts such as training which was used or the original training data.
- View model performance metrics: Links to observability tools tracking key metrics in real-time to understand how the model is performing in production.
- Identify model drift: Can be used as a reference and baseline, by integrating with other tools, to detect if the model’s predictions are deviating from expected behavior.
- Access model lineage: Understand the model’s origin and training details to diagnose and address performance issues.
- Audit model usage: Track who uses the model, ensuring compliance with data privacy and security regulations. Together with lineage, they provide very important capabilities in heavily regulated industries (e.g.: FSI, Healthcare, etc.) and with respect to country regulations (e.g.: GDPR, EU AI Act, etc.).
Benefits of Model Registry:
- Improved collaboration: Facilitate communication and collaboration between Data Scientists and MLOps engineers.
- Improved experiment management: Organize and track Experiments in a centralized location for better organization and accessibility.
- Version control: Track different versions of the model with different weight configurations, allowing comparisons and revert to previous versions if needed.
- Increased efficiency: Streamline model development and deployment processes.
- Enhanced governance: Ensure model compliance with regulations and organizational policies.
- Reproducibility: Enable recreating specific experiments and model versions.
- Better decision-making: Provide data-driven insights for improving model performance and business outcomes.
Conclusion:
By implementing a model registry, ACME Inc. can significantly enhance their MLOps platform’s functionality, enabling efficient model training, experimentation, and deployment. The Model Registry empowers Data Scientists, MLOps engineers, and Business analysts to collaborate effectively and make informed decisions based on reliable data and insights.
Next steps
- Follow the installation guide to set up Model Registry
- Run some examples following the getting started guide
- Explore the Model Catalog REST API reference
Feedback
Was this page helpful?
Thank you for your feedback!
We're sorry this page wasn't helpful. If you have a moment, please share your feedback so we can improve.