Introduction
Kubeflow Pipelines is a platform for building and deploying portable, scalable machine learning (ML) workflows based on Docker containers.
Quickstart
Run your first pipeline by following the pipelines quickstart guide.
What is Kubeflow Pipelines?
The Kubeflow Pipelines platform consists of:
- A user interface (UI) for managing and tracking experiments, jobs, and runs.
- An engine for scheduling multi-step ML workflows.
- An SDK for defining and manipulating pipelines and components.
- Notebooks for interacting with the system using the SDK.
The following are the goals of Kubeflow Pipelines:
- End-to-end orchestration: enabling and simplifying the orchestration of machine learning pipelines.
- Easy experimentation: making it easy for you to try numerous ideas and techniques and manage your various trials/experiments.
- Easy re-use: enabling you to re-use components and pipelines to quickly create end-to-end solutions without having to rebuild each time.
Kubeflow Pipelines is available as a core component of Kubeflow or as a standalone installation.
Due to kubeflow/pipelines#1700, the container builder in Kubeflow Pipelines currently prepares credentials for Google Cloud Platform (GCP) only. As a result, the container builder supports only Google Container Registry. However, you can store the container images on other registries, provided you set up the credentials correctly to fetch the image.
What is a pipeline?
A pipeline is a description of an ML workflow, including all of the components in the workflow and how they combine in the form of a graph. (See the screenshot below showing an example of a pipeline graph.) The pipeline includes the definition of the inputs (parameters) required to run the pipeline and the inputs and outputs of each component.
After developing your pipeline, you can upload and share it on the Kubeflow Pipelines UI.
A pipeline component is a self-contained set of user code, packaged as a Docker image, that performs one step in the pipeline. For example, a component can be responsible for data preprocessing, data transformation, model training, and so on.
See the conceptual guides to pipelines and components.
Example of a pipeline
The screenshots and code below show the xgboost-training-cm.py pipeline, which
creates an XGBoost model using structured data in CSV format. You can see the
source code and other information about the pipeline on
GitHub.
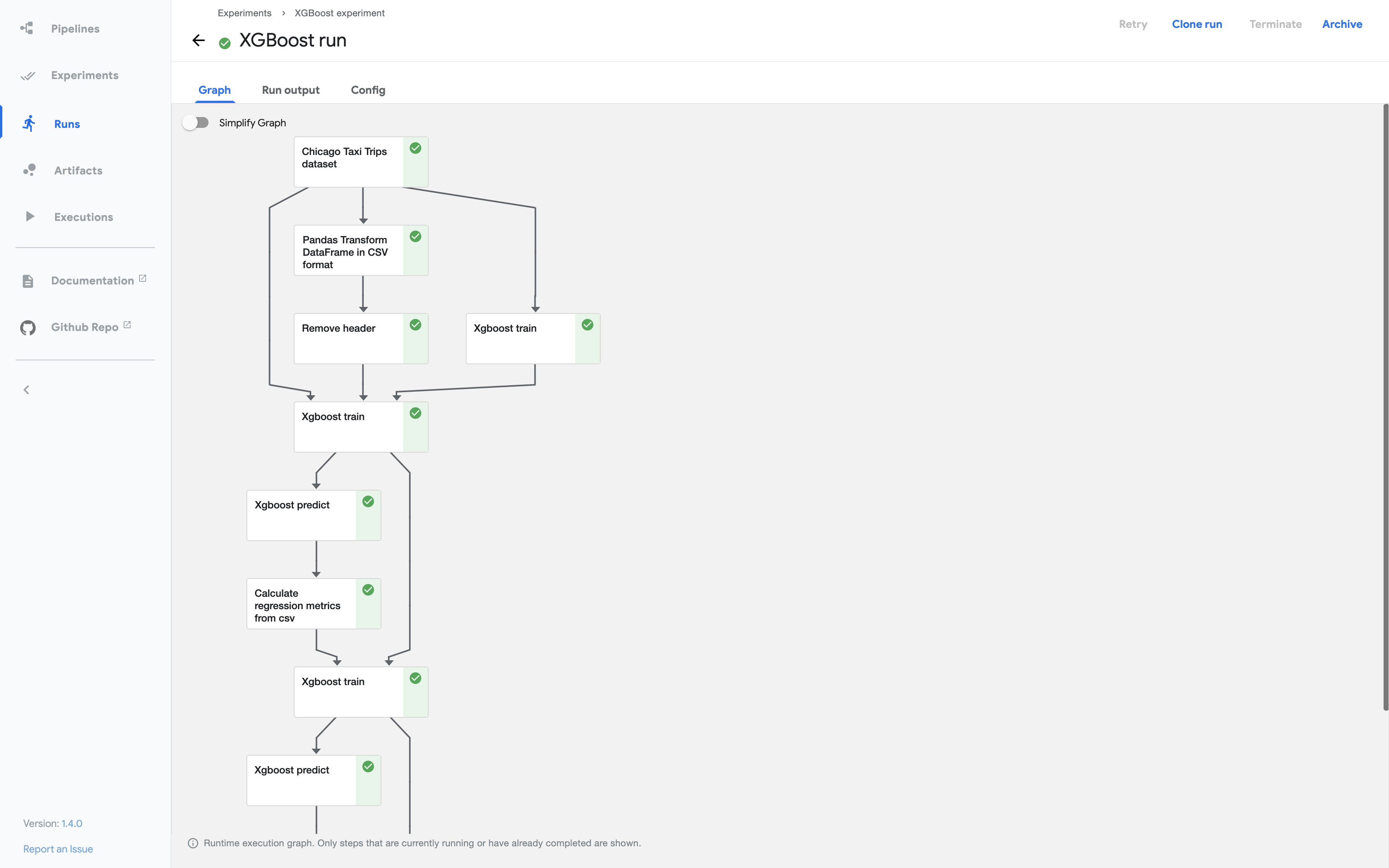
The runtime execution graph of the pipeline
The screenshot below shows the example pipeline’s runtime execution graph in the Kubeflow Pipelines UI:
The Python code that represents the pipeline
Below is an extract from the Python code that defines the
xgboost-training-cm.py pipeline. You can see the full code on
GitHub.
@dsl.pipeline(
name='XGBoost Trainer',
description='A trainer that does end-to-end distributed training for XGBoost models.'
)
def xgb_train_pipeline(
output='gs://your-gcs-bucket',
project='your-gcp-project',
cluster_name='xgb-%s' % dsl.RUN_ID_PLACEHOLDER,
region='us-central1',
train_data='gs://ml-pipeline-playground/sfpd/train.csv',
eval_data='gs://ml-pipeline-playground/sfpd/eval.csv',
schema='gs://ml-pipeline-playground/sfpd/schema.json',
target='resolution',
rounds=200,
workers=2,
true_label='ACTION',
):
output_template = str(output) + '/' + dsl.RUN_ID_PLACEHOLDER + '/data'
# Current GCP pyspark/spark op do not provide outputs as return values, instead,
# we need to use strings to pass the uri around.
analyze_output = output_template
transform_output_train = os.path.join(output_template, 'train', 'part-*')
transform_output_eval = os.path.join(output_template, 'eval', 'part-*')
train_output = os.path.join(output_template, 'train_output')
predict_output = os.path.join(output_template, 'predict_output')
with dsl.ExitHandler(exit_op=dataproc_delete_cluster_op(
project_id=project,
region=region,
name=cluster_name
)):
_create_cluster_op = dataproc_create_cluster_op(
project_id=project,
region=region,
name=cluster_name,
initialization_actions=[
os.path.join(_PYSRC_PREFIX,
'initialization_actions.sh'),
],
image_version='1.2'
)
_analyze_op = dataproc_analyze_op(
project=project,
region=region,
cluster_name=cluster_name,
schema=schema,
train_data=train_data,
output=output_template
).after(_create_cluster_op).set_display_name('Analyzer')
_transform_op = dataproc_transform_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=train_data,
eval_data=eval_data,
target=target,
analysis=analyze_output,
output=output_template
).after(_analyze_op).set_display_name('Transformer')
_train_op = dataproc_train_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=transform_output_train,
eval_data=transform_output_eval,
target=target,
analysis=analyze_output,
workers=workers,
rounds=rounds,
output=train_output
).after(_transform_op).set_display_name('Trainer')
_predict_op = dataproc_predict_op(
project=project,
region=region,
cluster_name=cluster_name,
data=transform_output_eval,
model=train_output,
target=target,
analysis=analyze_output,
output=predict_output
).after(_train_op).set_display_name('Predictor')
_cm_op = confusion_matrix_op(
predictions=os.path.join(predict_output, 'part-*.csv'),
output_dir=output_template
).after(_predict_op)
_roc_op = roc_op(
predictions_dir=os.path.join(predict_output, 'part-*.csv'),
true_class=true_label,
true_score_column=true_label,
output_dir=output_template
).after(_predict_op)
dsl.get_pipeline_conf().add_op_transformer(
gcp.use_gcp_secret('user-gcp-sa'))
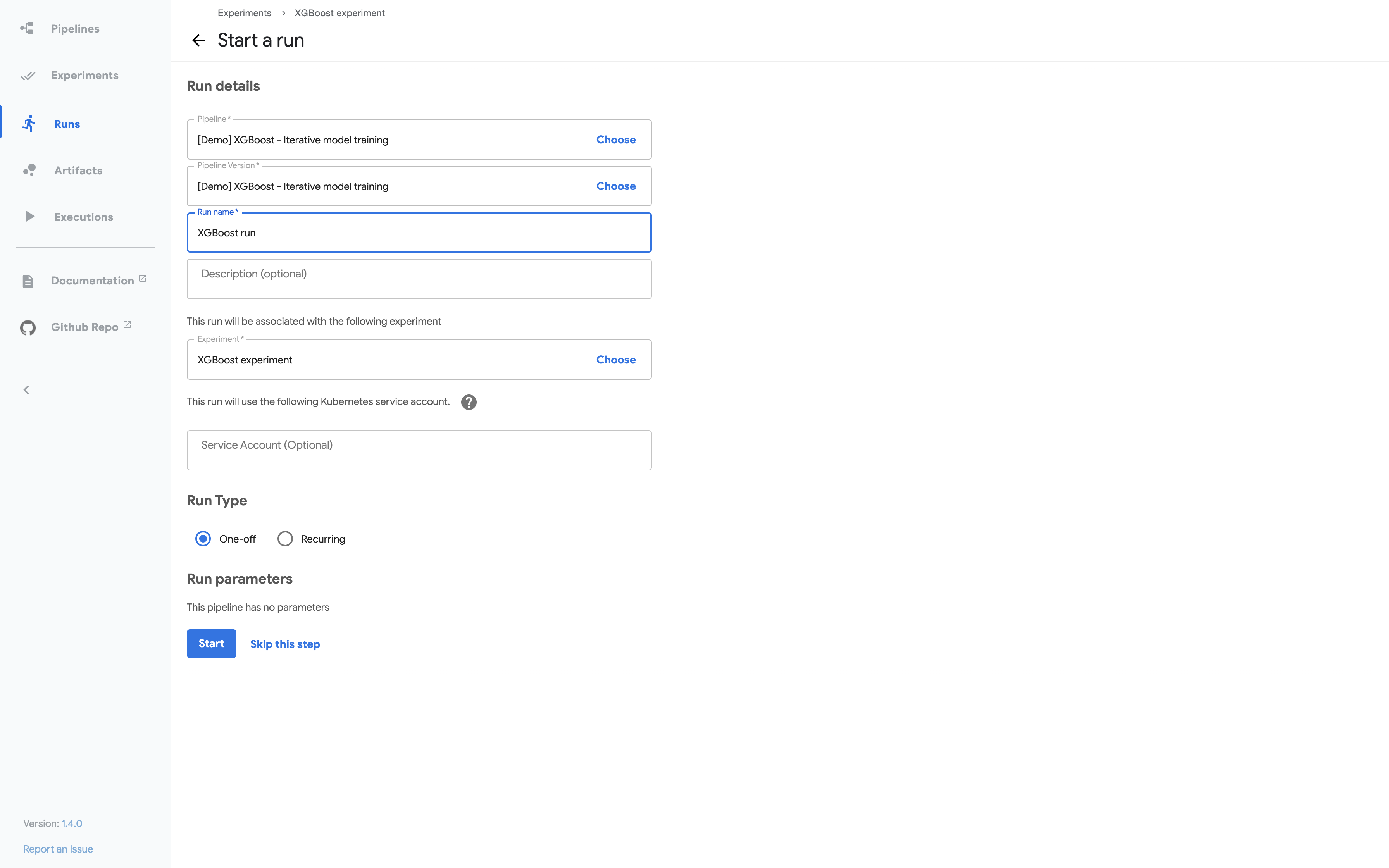
Pipeline input data on the Kubeflow Pipelines UI
The partial screenshot below shows the Kubeflow Pipelines UI for kicking off a run of the pipeline. The pipeline definition in your code determines which parameters appear in the UI form. The pipeline definition can also set default values for the parameters:
Outputs from the pipeline
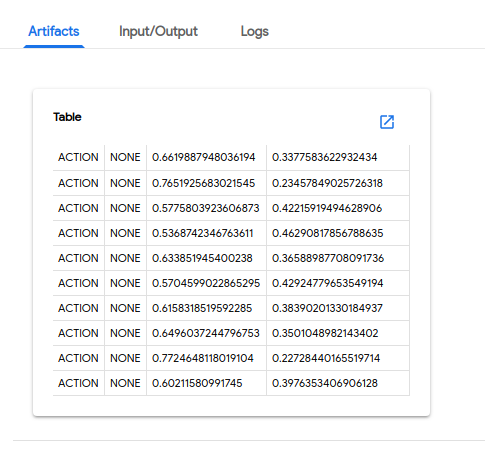
The following screenshots show examples of the pipeline output visible on the Kubeflow Pipelines UI.
Prediction results:
Confusion matrix:

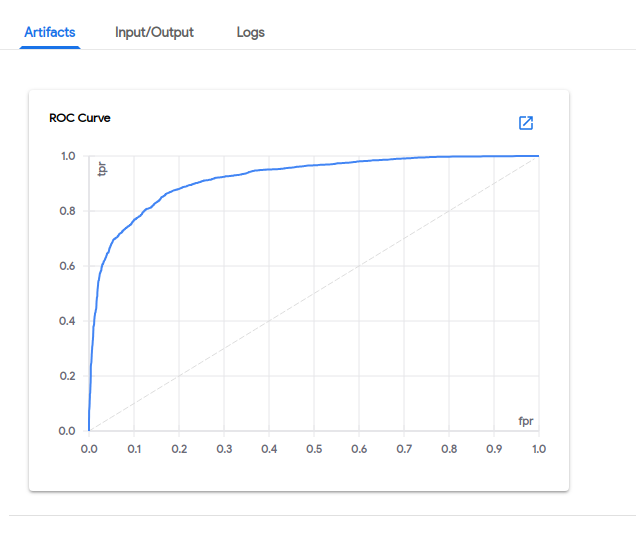
Receiver operating characteristics (ROC) curve:
Architectural overview
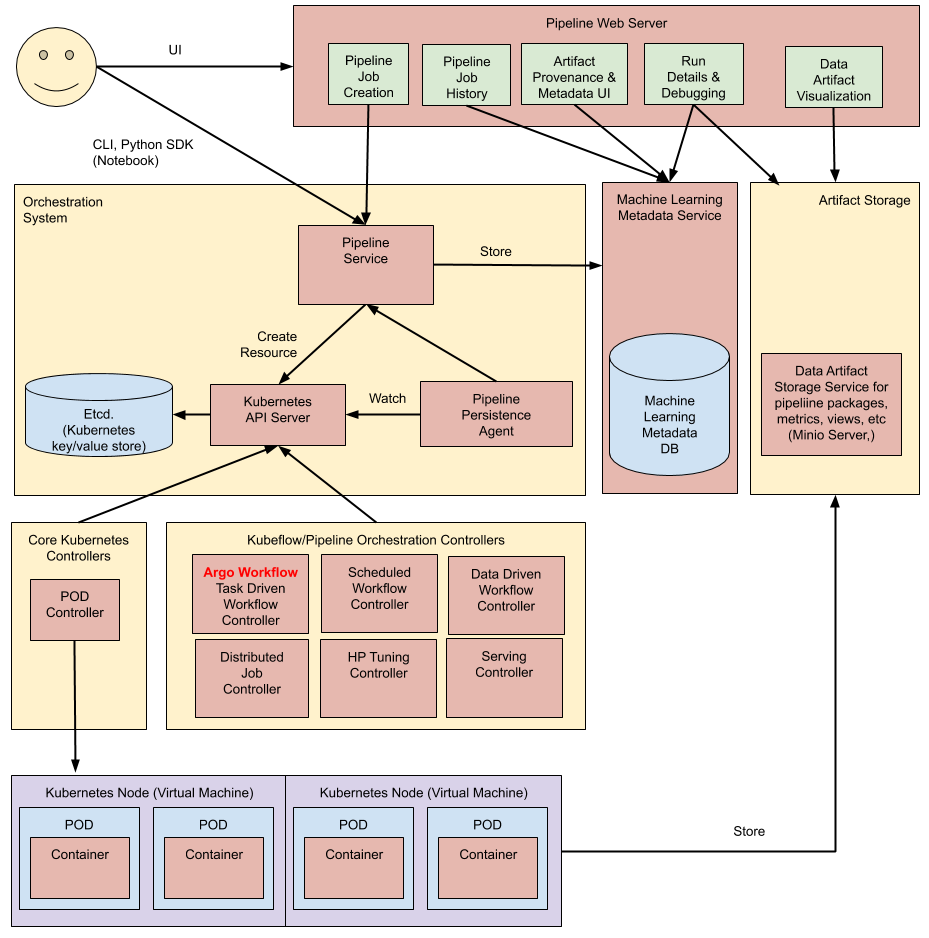
At a high level, the execution of a pipeline proceeds as follows:
Python SDK: You create components or specify a pipeline using the Kubeflow Pipelines domain-specific language (DSL).
DSL compiler: The DSL compiler transforms your pipeline’s Python code into a static configuration (YAML).
Pipeline Service: You call the Pipeline Service to create a pipeline run from the static configuration.
Kubernetes resources: The Pipeline Service calls the Kubernetes API server to create the necessary Kubernetes resources (CRDs) to run the pipeline.
Orchestration controllers: A set of orchestration controllers execute the containers needed to complete the pipeline. The containers execute within Kubernetes Pods on virtual machines. An example controller is the Argo Workflow controller, which orchestrates task-driven workflows.
Artifact storage: The Pods store two kinds of data:
Metadata: Experiments, jobs, pipeline runs, and single scalar metrics. Metric data is aggregated for the purpose of sorting and filtering. Kubeflow Pipelines stores the metadata in a MySQL database.
Artifacts: Pipeline packages, views, and large-scale metrics (time series). Use large-scale metrics to debug a pipeline run or investigate an individual run’s performance. Kubeflow Pipelines stores the artifacts in an artifact store like Minio server or Cloud Storage.
The MySQL database and the Minio server are both backed by the Kubernetes PersistentVolume subsystem.
Persistence agent and ML metadata: The Pipeline Persistence Agent watches the Kubernetes resources created by the Pipeline Service and persists the state of these resources in the ML Metadata Service. The Pipeline Persistence Agent records the set of containers that executed as well as their inputs and outputs. The input/output consists of either container parameters or data artifact URIs.
Pipeline web server: The Pipeline web server gathers data from various services to display relevant views: the list of pipelines currently running, the history of pipeline execution, the list of data artifacts, debugging information about individual pipeline runs, execution status about individual pipeline runs.
Next steps
- Follow the pipelines quickstart guide to deploy Kubeflow and run a sample pipeline directly from the Kubeflow Pipelines UI.
- Build machine-learning pipelines with the Kubeflow Pipelines SDK.
- Follow the full guide to experimenting with the Kubeflow Pipelines samples.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.