Introduction
What is Feast?
Feast is an open-source feature store that helps teams operate ML systems at scale by allowing them to define, manage, validate, and serve features to models in production.
The following diagram shows the architecture of Feast:
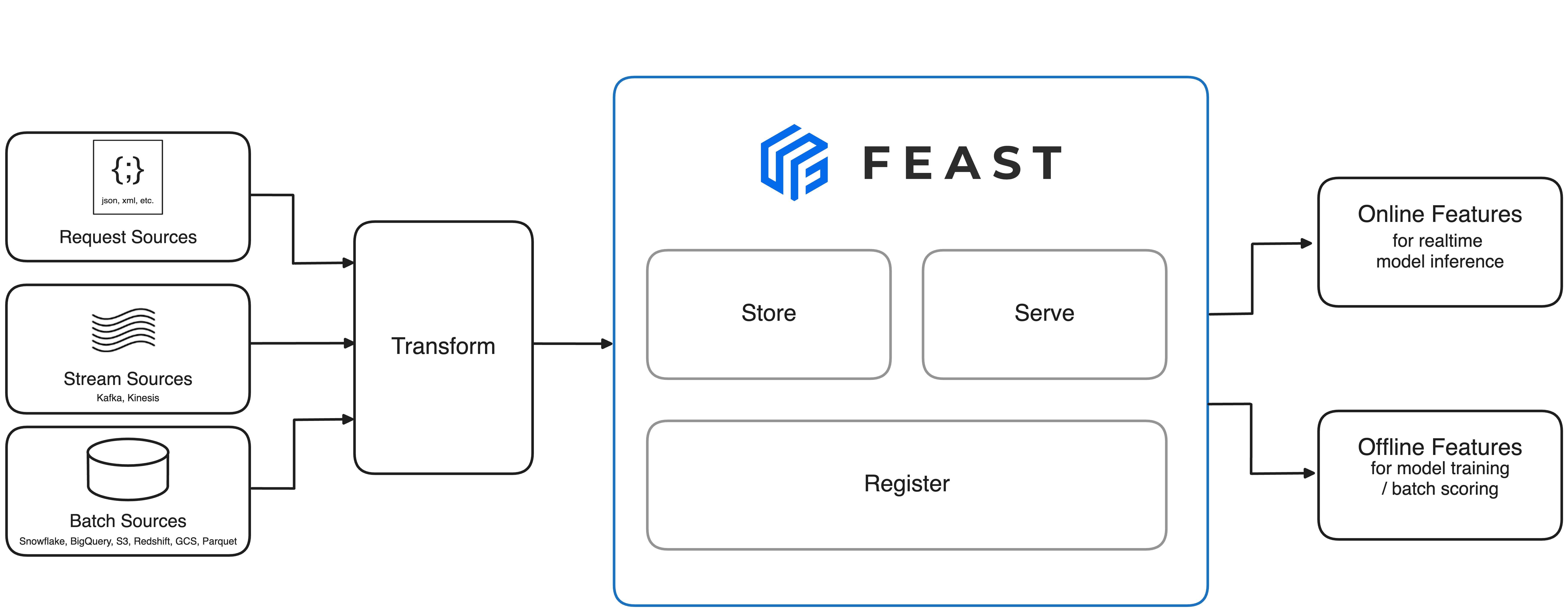
Feast provides the following functionality:
Load streaming, batch, and request-time data: Feast is built to be able to ingest data from a variety of bounded or unbounded sources. Feast allows users to ingest data from api-calls, streams, object stores, databases, or notebooks. Data that is ingested into Feast can be persisted in both online store and historical stores, which in turn is used for the creation of training datasets and serving features to online systems.
Standardized definitions: Feast becomes the single source of truth for all feature definitions and data within an organization. Teams are able to capture documentation, metadata, and metrics about features. This allows teams to communicate clearly about features, test feature data, and determine if a feature is both safe and relevant to their use cases.
Historical serving: Features that are persisted in Feast can be retrieved through its feature serving APIs to produce training datasets. Feast is able to produce massive training datasets that are agnostics of the data source that was used to ingest the data originally. Feast is also able to ensure point-in-time correctness when joining these data sources, which in turn ensures the quality and consistency of features reaching models.
Online serving: Feast exposes low latency serving APIs for all data that has been ingested into the system. This allows all production ML systems to use Feast as the primary data source when looking up real-time features.
Consistency between training and serving: Feast provides a consistent view of feature data through the use of a unified ingestion layer, unified serving API and canonical feature references. By building ML systems on feature references, teams abstract away the underlying data infrastructure and make it possible to safely move models between training and serving without a drop in data consistency.
Feature sharing and reuse: Feast provides a discovery and metadata API that allows teams to track, share, and reuse features across projects. Feast also provides a light-weight web UI to expose this metadata. Feast also decouples the process of creating features from the process of consumption, meaning teams that start new projects can begin by simply consuming features that already exist in the store, instead of starting from scratch.
Statistics and validation: Feast allows for the generation of statistics based on features within the systems. Feast has compatibility with TFDV, meaning statistics that are generated by Feast can be validated using TFDV. Feast also allows teams to capture TFDV schemas as part of feature definitions, allowing domain experts to define data properties that can be used for validating these features in other production settings like training, ingestion, or serving.
What is a feature store?
Feature stores are systems that reduce challenges faced by ML teams when productionizing features.
Some of the key challenges that feature stores help to address include:
Feature sharing and reuse: Engineering features is one of the most time-consuming activities in building an end-to-end ML system, yet many teams continue to develop features in silos. This leads to a high amount of re-development and duplication of work across teams and projects.
Serving features at scale: Models need data that can come from a variety of sources, including api-calls, event streams, data lakes, warehouses, or notebooks. ML teams need to be able to store and serve all these data sources to their models in a performant and reliable way. The challenge is scalable production of massive datasets of features for model training, and providing access to real-time feature data at low latency and high throughput in serving.
Consistency between training and serving: The separation between data scientists and engineering teams often lead to the re-development of feature transformations when moving from training to online serving. Inconsistencies that arise due to discrepancies between training and serving implementations frequently leads to a drop in model performance in production.
Point-in-time correctness: General purpose data systems are not built with ML use cases in mind and by extension don’t provide point-in-time correct lookups of feature data. Without a point-in-time correct view of data, models are trained on datasets that are not representative of what is found in production, leading to a drop in accuracy.
Data quality and validation: Features are business critical inputs to ML systems. Teams need to be confident in the quality of data that is served in production and need to be able to react when there is any drift in the underlying data.
How to use Feast with Kubeflow?
Feast can be run on the same Kubernetes cluster as Kubeflow, and may be used to serve features for models that are trained in Kubeflow Pipelines and deployed with KServe.
Requirements
- A Kubernetes cluster with Kubeflow installed
- A database to use as an offline store (BigQuery, Snowflake, Redshift, etc.)
- A database to use as an online store (Redis, Datastore, DynamoDB, etc.)
- A bucket (S3, GCS, SeaweedFS, etc.) or SQL Database (Postgres, MySQL, etc.) to use as the feature registry
- A workflow engine (Airflow, Kubeflow Pipelines, etc.) to materialize data and run other Feast jobs
Installation
To use Feast with Kubeflow, please follow the following steps
- Install the Feast Python package
- Create a feature repository
- Deploy your feature store
- Create a training dataset
- Load features into the online store
- Read features from the online store
Please their production usage guide for best practices when running Feast in production.
Using Feast APIs
Once Feast is installed within the same Kubernetes cluster as Kubeflow, users can access its APIs directly without any additional steps.
Feast provides the following categories of APIs:
- Feature definition and management:
- Feast provides both a Python SDK and CLI for interacting with Feast Core.
- Feast Core allows users to define and register features and entities and their associated metadata and schemas.
- The Python SDK is typically used from within a Jupyter notebook by end users to administer Feast, but ML teams may opt to version control feature specifications in order to follow a GitOps based approach.
- Model training:
- The Feast Python SDK can be used to trigger the creation of training datasets.
- The most natural place to use this SDK is to create a training dataset as part of a Kubeflow Pipeline prior to model training.
- Model serving:
- The Feast Python SDK can also be used for online feature retrieval. This client is used to retrieve feature values for inference with model-serving-systems like KServe.
Please see the Feast tutorials page for more information on using Feast.
Feedback
Was this page helpful?
Thank you for your feedback!
We're sorry this page wasn't helpful. If you have a moment, please share your feedback so we can improve.